接下來幾個章節,會介紹Q-learning的進階方法,筆者可親自針對原本專案的Q-learning修改試試,但因為電腦都在跑別的東西了,所以實際效果如何或怎樣就讓讀者親自實驗囉XD 先說下每個方法對於每個環境並非都適用,各種better method可參考Rainway(先爆雷XD),裡面有各種方法的比較使用,很詳盡,對於想更認識Q-learning進階方法的讀者來說,非常推薦!
好哩之前講過DQN會有收斂不穩定的問題,這章將分享個有效的解決方案-Double DQN。
我們之前介紹到DQN會把target-net做Q現實的部分,到一定次數才會用evaluate-net參數copy給target-net更新,原本是要減緩更新幅度以此增加穩定性,但因為target-net的參數一段時間才會更新,Q現實值對學習不一定那麼有效果。有可能當下state採取action1是對的,但因為target-net的舊參數關係,可能輸出成action2的值。
記得在程式碼Q-target跟Q-evaluate兩個網路是獨立開來的嗎?其實可讓Q-target的action由Q-evaluate來決定就可以囉!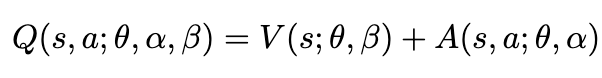
先來補充之前沒提到的target-net,這先複習上章節的Q更新程式碼
targets[i] = model.predict(state_t)
Q_sa = model.predict(state_t1)
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa)
補上之前沒提到的target-net
targets[i] = model.predict(state_t)
Q_sa = model_target.predict(state_t1)
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa)
換成Double DQN,我們會對target-net的值不直接取最大,而是取evaluate最大值的index,然後才對target-net取值。
Q_index = model_evaluate.predict(state_t1)
Q_index = np.argmax(Q_index)
Q_sa = model_target.predict(state_t1)
targets[i, action_t] = reward_t + GAMMA * Q_sa[0][Q_index]
Q-learning的貪婪算法目標是取最大值,這讓我們在很多場景能成功跑Q-learning,但這個特性也帶來了些問題,未來會在做補充,順便提解決方案。這幾個章講解的Q-learning優化其實內容稍嫌不充分,建議還是可以去翻翻論文了解更多細節,好哩今天這我們明天見拉!
1.Natual DQN →https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
2.Double DQN → https://arxiv.org/pdf/1509.06461.pdf


 iThome鐵人賽
iThome鐵人賽